Introducción
El modelado de previsiones presupuestarias constituye uno de los escenarios más desafiantes en el campo del diseño y explotación de modelos de datos en Power BI. Las estructuras de datos en dicha herramienta se basan en el motor de Analysis Services y en la tecnología xVelocity (previamente denominada VertiPaq); de hecho, al ejecutar un archivo .pbix se inicia a su vez una instancia tabular de SSAS (SQL Server Analysis Services) en un puerto aleatorio.
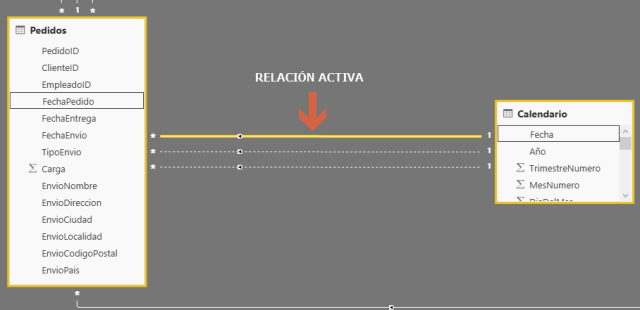
En el modelo tabular, a diferencia de lo que ocurre en el multidimensional, las relaciones entre tablas se establecen utilizando una sola columna, que requiere que sus valores sean únicos en la tabla de búsqueda, por lo que no podemos definir relaciones entre hechos y dimensiones a diferentes granularidades directamente.
En este artículo veremos cómo manejar las relaciones entre tablas con distinta granularidad, escenario típico cuando tratamos de incluir previsiones presupuestarias en nuestro modelo. En este tema cada empresa es un mundo y todo depende del nivel de detalle al que se hayan definido dichas previsiones, pero el problema consiste a menudo en que la granularidad del presupuesto es completamente distinta a la del resto del modelo de datos.