Todo el contenido de este blog se migra a https://bicontrolling.com donde seguirá con su actividad habitual.
¡Os esperamos!

Microsoft Power BI para los departamentos contable y financiero de la empresa
Todo el contenido de este blog se migra a https://bicontrolling.com donde seguirá con su actividad habitual.
¡Os esperamos!
El modelado de previsiones presupuestarias constituye uno de los escenarios más desafiantes en el campo del diseño y explotación de modelos de datos en Power BI. Las estructuras de datos en dicha herramienta se basan en el motor de Analysis Services y en la tecnología xVelocity (previamente denominada VertiPaq); de hecho, al ejecutar un archivo .pbix se inicia a su vez una instancia tabular de SSAS (SQL Server Analysis Services) en un puerto aleatorio.
En el modelo tabular, a diferencia de lo que ocurre en el multidimensional, las relaciones entre tablas se establecen utilizando una sola columna, que requiere que sus valores sean únicos en la tabla de búsqueda, por lo que no podemos definir relaciones entre hechos y dimensiones a diferentes granularidades directamente.
En este artículo veremos cómo manejar las relaciones entre tablas con distinta granularidad, escenario típico cuando tratamos de incluir previsiones presupuestarias en nuestro modelo. En este tema cada empresa es un mundo y todo depende del nivel de detalle al que se hayan definido dichas previsiones, pero el problema consiste a menudo en que la granularidad del presupuesto es completamente distinta a la del resto del modelo de datos.
El denominado Machine Learning es una rama de la inteligencia artificial que utiliza algoritmos con el objetivo de automatizar la construcción de modelos analíticos. Se basa en la idea de que los sistemas pueden aprender de observaciones pasadas, identificar patrones, tomar decisiones y predecir comportamientos futuros sin necesidad de programación explicita.
Dentro del Machine Learning clásico nos encontramos con dos tipos principales de tareas: supervisadas y no supervisadas. La diferencia entre ambas reside en que el aprendizaje supervisado se realiza utilizando datos con etiquetas ya identificadas, o en otras palabras, tenemos un conocimiento previo de cuáles pueden ser los valores de salida para nuestras muestras. Por lo tanto, el objetivo del aprendizaje supervisado es aprender una función que, dada una muestra de datos y salidas posibles, se aproxime mejor a la relación entre entrada y salida observable en los datos. El aprendizaje no supervisado, por otro lado, no tiene resultados etiquetados, por lo que su objetivo es inferir la estructura natural presente dentro de un conjunto de puntos de datos.
Seguir leyendo «Aprendizaje supervisado con Python en Power BI: Clasificación»
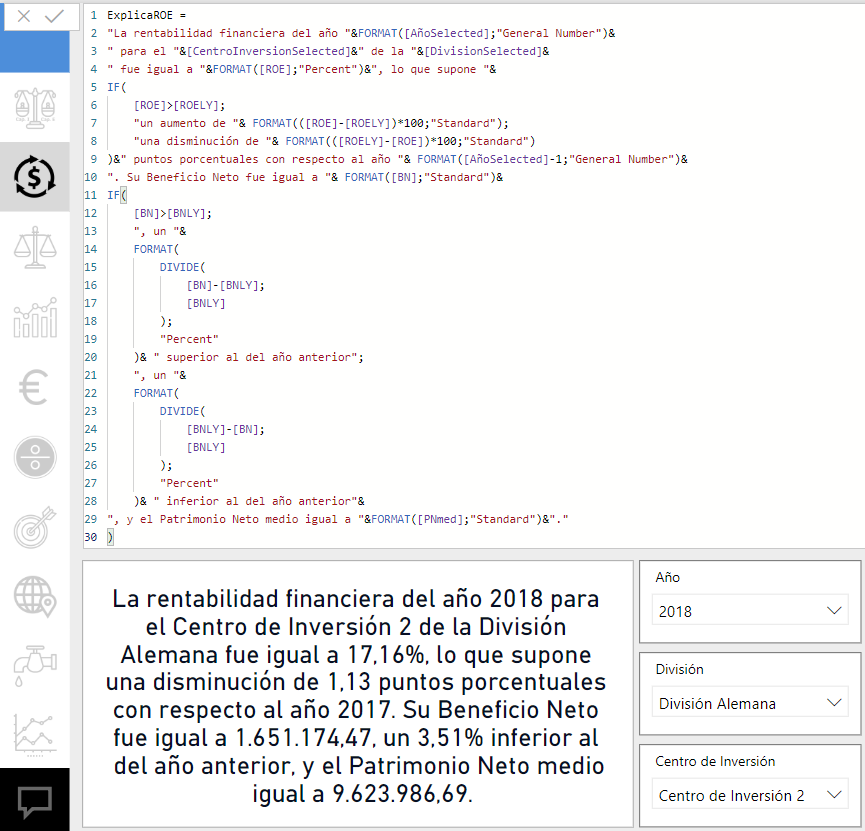
Siempre me ha gustado crear medidas de texto que sean capaces de interpretar y explicar ciertos resultados en lenguaje natural al usuario. Creando expresiones DAX mediante el uso de variables, campos y otros elementos programáticos conseguiremos que, en función de los filtros seleccionados por el usuario, el texto de la visualización se modifique dinámicamente, actuando casi como un analista de datos automatizado capaz de evaluar distintos escenarios y ofrecernos de una forma muy sencilla la respuesta que buscamos.
Por ejemplo, en la siguiente imagen podemos ver una medida que nos explica los aspectos clave de la rentabilidad financiera teniendo en cuenta el contexto de filtro aplicado por el usuario:
La integración de Python en Power BI es, sin duda, una de las funcionalidades introducidas por el equipo más importantes hasta la fecha. Al igual que R, Python nos ofrece numerosas posibilidades para realizar tareas durante el proceso de ETL en nuestras propias consultas, y crear visualizaciones atractivas y útiles mediante el uso de sus librerías orientadas a la representación gráfica de información estadística. Además, nos proporciona la capacidad de incrementar de forma exponencial la competencia analítica de nuestros informes y cuadros de mando, mediante el uso de módulos de Machine Learning capaces de identificar patrones complejos en los datos con el objetivo de predecir comportamientos futuros, proporcionándonos información de alto valor para la toma de decisiones de negocio.
El lenguaje de programación Phyton cuenta con librerías orientadas al análisis de datos con multitud de funciones y métodos que podemos usar durante las etapas de transformación y limpieza, antes de cargar las consultas al modelo. La librería pandas nos permite manipular Data Frames con un gran número de funciones diseñadas específicamente para los procesos de preparación de datos. Vamos a ver un ejemplo donde tenemos una tabla con datos de clientes que contiene valores null en las columnas que especifican el peso y la altura de cada uno de ellos:
Como vimos en una entrada anterior, cuando diseñamos un modelo de datos analítico, el enfoque principal debe situarse en lograr un diseño que favorezca la simplicidad en la exploración y agregación de los datos, a la vez que en obtener un rendimiento óptimo en la realización de consultas.
Las estructuras altamente normalizadas, con dimensiones organizadas en esquemas de copo de nieve que principalmente nos encontraremos en los sistemas de procesamiento de transacciones, no serán adecuadas para satisfacer las necesidades analíticas de la empresa teniendo la comprensibilidad del modelo por parte de los usuarios y la velocidad de consulta como objetivos principales. El hecho de disponer de más de una tabla por cada dimensión de la tabla de hechos de un proceso de negocio implica tener que realizar código más complejo para realizar una consulta que a su vez se ejecutará en un tiempo mayor, debido en parte al mayor número de relaciones.
Seguir leyendo «Desnormalizando dimensiones de forma eficiente»
En casi cualquier modelo de datos que diseñemos será imprescindible disponer de una dimensión temporal que nos permita filtrar y segmentar los datos de las tablas de hechos en función de los atributos temporales que nos interesen en cada momento. La dimensión temporal más común y útil corresponde a aquella de nivel de granularidad diario, donde tendremos un registro por cada día del periodo abarcado por dicha dimensión.
Por otra parte, atributos relacionados con la dimensión horaria utilizados para describir los eventos registrados en las tablas de hechos aparecen con mucha menor frecuencia. No obstante, en algunas ocasiones en las que el tiempo queda registrado con un nivel de detalle inferior al día, la posibilidad de segmentar los datos por dichos atributos se convierte en uno de los temas principales a la hora de diseñar un almacén de datos analítico.
Los informes económico-financieros, basados principalmente en las normas de registro y valoración de los diferentes elementos que componen los estados financieros que deben elaborarse bajo el Plan General de Contabilidad, han sido históricamente un proceso complejo y estático, que proporciona información limitada y con horizontes temporales predefinidos (cierre trimestral, anual…), con la que no podemos interactuar y profundizar en aquellos aspectos que nos interesan en cada momento, algo necesario si realmente queremos poder obtener información relevante y evaluar en detalle la evolución de las magnitudes empresariales en relación a sus objetivos.
Las herramientas de inteligencia de negocios nos permiten ir mucho más allá en la elaboración de este tipo de informes, tanto si se basan principalmente en la contabilidad financiera y se dirigen a los grupos de interés externos a la empresa, como si utilizan un amplio abanico de orígenes de datos internos y externos, y sus destinatarios principales son los directivos de la empresa, con el objetivo de facilitar la toma de decisiones en cualquier momento y lugar, proporcionando un instrumento de planificación, información y control simultáneo y dinámico de las diferentes partes de una organización, aumentando la capacidad de la empresa de crear valor económico.
Un escenario muy frecuente cuando utilizamos bases de datos relacionales como origen de datos principal de un modelo que reproduce un proceso de negocio, como pueden ser las ventas de una empresa, es encontrarnos con dos tablas de hechos con distinta granularidad para describir el mismo proceso. Una de ellas contendrá un registro por cada ticket, albarán o factura emitida con los atributos generales de fecha, cliente, base imponible, impuesto etc., y la otra irá un poco más allá y registrará las ventas a nivel de cada producto vendido, es decir, existirá un registro por cada línea de detalle dentro de cada documento.
En la siguiente imagen podemos ver un ejemplo de esta situación, donde tanto los albaranes como las facturas presentan una estructura de datos del tipo descrito:
Seguir leyendo «Estructuras jerárquicas en tablas de hechos»
En cualquier sistema de BI, podemos crear cálculos o medidas de 3 tipos distintos:
SUM() para agregar sus valores en función de cualquier atributo dimensional. Un ejemplo típico pueden ser las ventas, cuyo total podemos desglosar en la suma de las ventas por producto, por mes, por cliente, así como por cualquier otro atributo que nos interese para filtrar o segmentar dicho cálculo.SUM() para agregar sus valores solo en función de determinadas dimensiones, pero se necesita otro tipo de agregación distinta para segmentar por los atributos de alguna otra dimensión. Ejemplos típicos de este tipo de medidas son las tablas de inventarios y las de los saldos de las cuentas contables, que no pueden agregarse en función de los atributos de la dimensión temporal mediante una suma simple.SUM() en función de ninguno de los atributos presentes en el modelo de datos. Un ejemplo típico es el tipo de cambio de una moneda respecto a otra.