Introducción
El denominado Machine Learning es una rama de la inteligencia artificial que utiliza algoritmos con el objetivo de automatizar la construcción de modelos analíticos. Se basa en la idea de que los sistemas pueden aprender de observaciones pasadas, identificar patrones, tomar decisiones y predecir comportamientos futuros sin necesidad de programación explicita.
Dentro del Machine Learning clásico nos encontramos con dos tipos principales de tareas: supervisadas y no supervisadas. La diferencia entre ambas reside en que el aprendizaje supervisado se realiza utilizando datos con etiquetas ya identificadas, o en otras palabras, tenemos un conocimiento previo de cuáles pueden ser los valores de salida para nuestras muestras. Por lo tanto, el objetivo del aprendizaje supervisado es aprender una función que, dada una muestra de datos y salidas posibles, se aproxime mejor a la relación entre entrada y salida observable en los datos. El aprendizaje no supervisado, por otro lado, no tiene resultados etiquetados, por lo que su objetivo es inferir la estructura natural presente dentro de un conjunto de puntos de datos.
Existen dos tipos de problemas dentro del aprendizaje automático supervisado, los de regresión y los de clasificación. La principal diferencia entre ellos es que la variable de salida (o dependiente) en la regresión es numérica (o continua), mientras que en la clasificación es categórica (o discreta).
En este artículo nos centraremos en aplicar algunos de los principales algoritmos usados para resolver problemas de clasificación, con el objetivo de predecir la pérdida de un cliente (que será nuestra variable dependiente) utilizando las variables predictoras o características de las que disponemos en nuestro modelo de datos.
Análisis de datos exploratorio
Aunque todas las etapas del aprendizaje supervisado las podemos realizar directamente desde la funcionalidad de Scripts de Phyton en el editor de consultas de Power BI, por comodidad, en este artículo utilizaremos un Jupyter Notebook. Vamos a comenzar cargando nuestra tabla en un DataFrame de pandas y observando los 5 primeros registros:

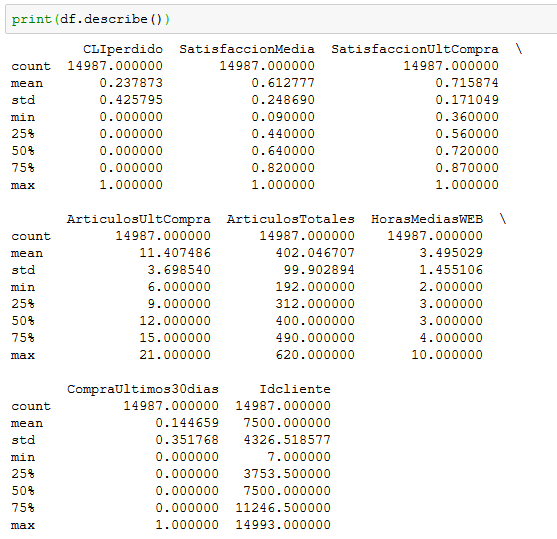
Como podemos observar, nos encontramos ante un problema de clasificación binaria. Vemos también que nuestros datos son una combinación de categorías y números, lo que significa que deberemos codificar los datos categóricos para presentarlos como números, con el objetivo de que nuestro modelo de aprendizaje automático pueda trabajar correctamente con ellos, para lo que utilizaremos la función LabelEncoder() de la biblioteca de preprocesamiento de scki-kit. Tenemos 14987 registros y 10 características, además de nuestra variable objetivo:

Vamos a generar estadísticas descriptivas que resuman la tendencia central, la dispersión y la forma de la distribución de nuestro conjunto de datos, y un diagrama de caja para cada variable numérica, que nos dará una idea más clara de la distribución de las variables de entrada:
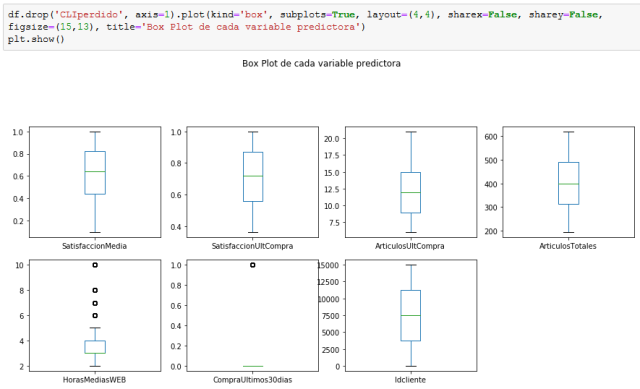
Podemos ver que los valores numéricos no tienen la misma escala y, como la mayoría de los algoritmos de aprendizaje automático tienen en cuenta solo la magnitud de las mediciones y no las unidades de dichas mediciones, tendremos que modificar la escala del conjunto de entrenamiento. Como nuestros datos no tienen demasiados valores atípicos utilizaremos la función MinMaxScaler() con los parámetros de rango por defecto, es decir, entre 0 y 1.
Antes de seguir vamos a generar histogramas para cada variable predictora en busca de correlaciones visuales:
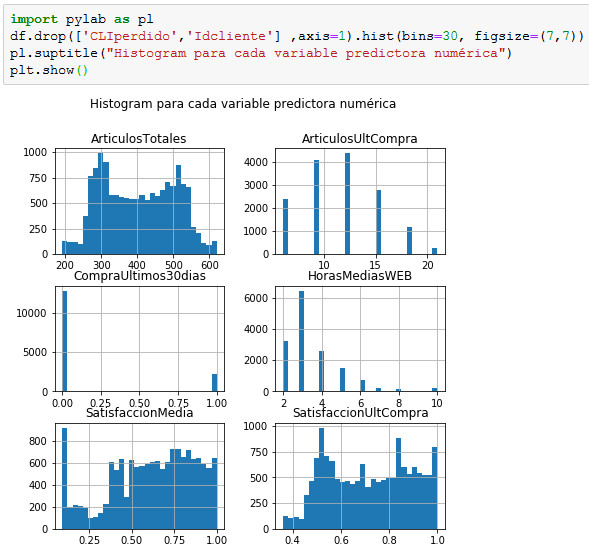
Como se observa, parece existir cierta correlación entre el número de artículos comprados total y el nivel de satisfacción en la última compra, lo que nos sugiere cierta relación predictiva.
Etapas del proceso de aprendizaje automático supervisado
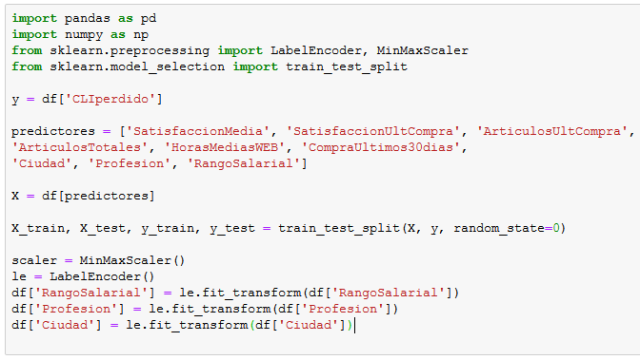
Una vez realizado el análisis exploratorio visual, vamos a desarrollar las etapas del aprendizaje automático. Importamos las librerías y funciones necesarias para llevar a cabo el proceso, establecemos la variable dependiente (y) y guardamos en la variable predictores la lista que contiene todas las características que funcionarán como predictoras.
A continuación dividimos nuestro conjunto de datos en conjunto de entrenamiento y conjunto de prueba, aplicamos ajuste (scaling) con el objetivo de acotar el rango de valores de cada atributo a fin de que coincidan entre si los rangos de todos los atributos del conjunto de datos y finalmente utilizamos LabelEncoder() para transformar los datos categóricos de texto en etiquetas numéricas:
Ahora vamos a implementar distintos algoritmos de aprendizaje supervisado y evaluar la precisión de cada uno de ellos en los dos conjuntos de datos. En el mundo del Machine Learning no existe un algoritmo único que funcione siempre mejor que los demás para resolver cualquier problema:
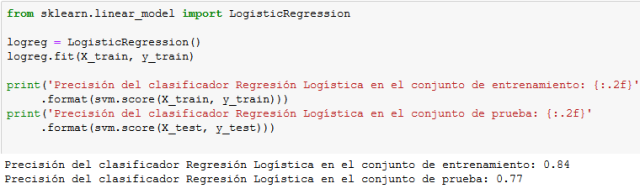
Regresión Logística
K vecinos más cercanos

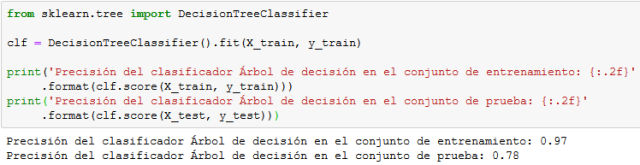
Árboles de decisión
Naive Bayes gaussiano
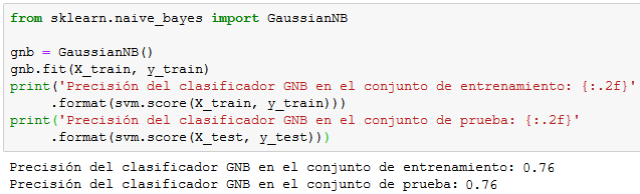
Como podemos ver, el algoritmo basado en árboles de decisión es el que nos proporciona mayor precisión en el conjunto de prueba.
Añadir columnas en nuestra consulta de Power BI
Aunque no sea el algoritmo que más precisión nos otorga en la resolución de nuestro problema, la Regresión Logística eso uno de los más utilizados en la resolución de problemas de clasificación porque devuelve la probabilidad (como valor entre 0 y 1) de que una muestra pertenezca a una clase particular. Esto es extremadamente útil en casos como la predicción de la pérdida de un cliente, ya que no solo nos gustaría saber si el cliente se perderá, sino también las probabilidades de que esto ocurra, con el objetivo de vigilar aquellos que se encuentren en riesgo y proceder a la realización de las acciones oportunas para evitarlo.
Por esta razón, vamos a utilizar dicho algoritmo para añadir en el editor de consultas de Power BI, no solo la columna de predicción, sino también una que nos indique la probabilidad de pérdida del cliente en cuestión:

Cuando tenemos todo el código listo, lo pegamos en la ventana de Scripts de Python del editor de consultas:
Y finalmente obtendremos la información deseada:
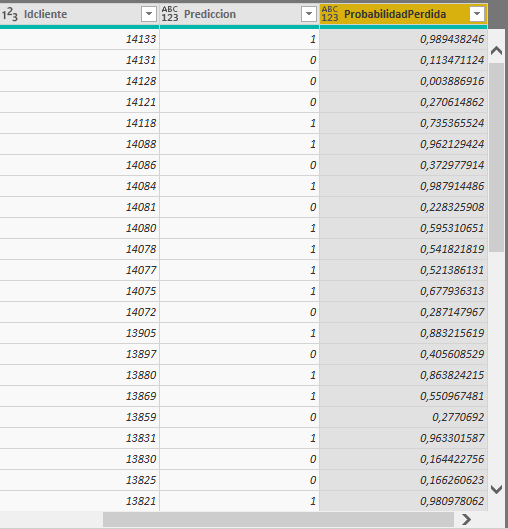
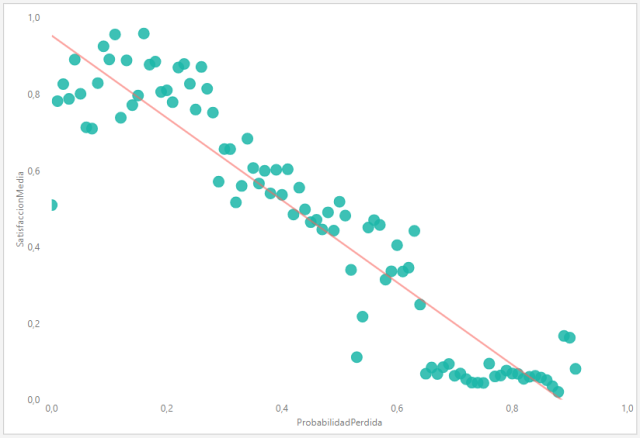
Cada vez que actualicemos nuestras consultas, el Script de Python se ejecutará, por lo que tendremos la capacidad de filtrar y segmentar estas columnas introducidas de la misma manera que cualquier otra información presente en nuestro modelo de datos. Por ejemplo, en la siguiente imagen podemos observar un gráfico de dispersión que nos muestra claramente la correlación negativa entre el nivel de satisfacción del cliente y la probabilidad de perderlo, habiendo filtrado solamente los clientes de un rango salarial y una ciudad determinados, de manera que podamos tener siempre identificados aquellos clientes en riesgo de irse a la competencia: