
Introducción
El modelado de previsiones presupuestarias constituye uno de los escenarios más desafiantes en el campo del diseño y explotación de modelos de datos en Power BI. Las estructuras de datos en dicha herramienta se basan en el motor de Analysis Services y en la tecnología xVelocity (previamente denominada VertiPaq); de hecho, al ejecutar un archivo .pbix se inicia a su vez una instancia tabular de SSAS (SQL Server Analysis Services) en un puerto aleatorio.
En el modelo tabular, a diferencia de lo que ocurre en el multidimensional, las relaciones entre tablas se establecen utilizando una sola columna, que requiere que sus valores sean únicos en la tabla de búsqueda, por lo que no podemos definir relaciones entre hechos y dimensiones a diferentes granularidades directamente.
En este artículo veremos cómo manejar las relaciones entre tablas con distinta granularidad, escenario típico cuando tratamos de incluir previsiones presupuestarias en nuestro modelo. En este tema cada empresa es un mundo y todo depende del nivel de detalle al que se hayan definido dichas previsiones, pero el problema consiste a menudo en que la granularidad del presupuesto es completamente distinta a la del resto del modelo de datos.
Para ser capaces de integrar los datos presupuestarios en nuestro modelo correctamente podemos recurrir a distintas técnicas. Probablemente la primera que nos viene a la mente es la de agrupar, durante el proceso de ETL, en el origen de datos o en el editor de consultas, la tabla de ventas a la granularidad deseada, es decir, aquella que coincide con la del presupuesto. Si no queremos (o no podemos) modificar los datos ya cargados en el modelo, siempre podemos utilizar DAX como herramienta de modelado para resolver este tipo de escenarios. Aprovechando el lenguaje DAX, podemos crear modelos muy avanzados con prácticamente cualquier tipo de relación, lo que nos proporcionará una importante flexibilidad en el diseño de los mismos.
Relaciones virtuales con DAX
Imaginemos que disponemos del siguiente esquema dimensional para el proceso de ventas de una empresa:

Y el presupuesto de ventas del año 2019 que nos proporcionan para integrar en el modelo es el siguiente:

En el modelo, cada registro de la tabla de ventas está relacionado con un producto y una fecha en concreto, al contrario que en el presupuesto, donde las agrupaciones de ambas dimensiones están definidas a un nivel jerárquico superior, la categoría de producto y el mes del año. Tenemos que trabajar por tanto con datos a distintas granularidades, que nos impiden definir relaciones físicas, porque ninguna de las tablas involucradas tiene una columna que satisfaga la condición de unicidad requerida por una relación de uno-a-varios.
En estos casos podemos utilizar DAX para definir relaciones virtuales entre los atributos dimensionales y las categorías del presupuesto al nivel correspondiente.
Para ello es conveniente disponer, en nuestra dimensión temporal y en nuestra tabla de presupuesto, de una columna que agrupe el mes y el año correspondientes a cada registro. Podemos añadir dicha columna en el editor de consultas con M:
AñoMesNumerosAñadido = Table.AddColumn(Origen, "AñoMesNumeros", each [Año]*100 + [MesNumero])
O hacerlo con DAX directamente en la consulta ya cargada en el modelo:
AñoMesNumeros =
Calendario[Año] * 100 + Calendario[MesNumero]
Tras realizar la misma operación en el presupuesto, podemos usar la función TREATAS() para transferir un contexto de filtro de una tabla a otra, simulando el comportamiento de una relación física definida en el modelo de datos:
VentasPresupuestas2019 =
CALCULATE (
SUM ( Presupuesto[Ventas] );
TREATAS ( VALUES ( Calendario[AñoMesNumeros] );
Presupuesto[AñoMesNumeros] );
TREATAS ( VALUES ( Productos[Categoria] );
Presupuesto[Categoria] )
)
Si la versión de DAX que estamos utilizando no soporta la función TREATAS() , podemos utilizar la función INTERSECT() para transferir el contexto de filtro de la misma manera:
INTERSECTVentasPresup2019 =
CALCULATE (
SUM ( Presupuesto[Ventas] );
INTERSECT (
ALL ( Presupuesto[AñoMesNumeros] );
VALUES ( Calendario[AñoMesNumeros] )
);
INTERSECT ( ALL ( Presupuesto[Categoria] ); VALUES ( Productos[Categoria] ) )
)
Por último, si nuestra versión tampoco soporta INTERSECT(), siempre podemos recurrir al uso de FILTER() y CONTAINS() para obtener el mismo resultado. Eso sí, pagando un precio mayor respecto al rendimiento:
FILTERVentasPresup2019 =
CALCULATE (
SUM ( Presupuesto[Ventas] );
FILTER (
ALL ( Presupuesto[AñoMesNumeros] );
CONTAINS (
VALUES ( Calendario[AñoMesNumeros] );
Calendario[AñoMesNumeros]; Presupuesto[AñoMesNumeros]
)
);
FILTER (
ALL ( Presupuesto[Categoria] );
CONTAINS (
VALUES ( Productos[Categoria] );
Productos[Categoria]; Presupuesto[Categoria]
)
)
)
De las 3 formas obtendremos el mismo resultado:

Ya podemos explorar los datos relativos a las ventas reales, presupuestadas y las desviaciones experimentadas en una misma visualización, y a la granularidad con la que se definieron los presupuestos:

En los ejemplos anteriores hemos utilizado la columna calculada AñosMesNumeros para propagar los filtros de nuestra dimensión temporal, pero también podemos realizar la misma operación utilizando las 2 columnas por separado, sin necesidad de combinarlas en una sola. El siguiente código realiza la misma operación utilizando las 2 columnas presentes originalmente en el modelo, usando TEATRAS(), la mejor manera de implementar una relación virtual en términos de rendimiento:
TREATAS2col =
CALCULATE (
SUM ( Presupuesto[Ventas] );
TREATAS (
SUMMARIZE ( Calendario; Calendario[Año]; Calendario[MesNumero] );
Presupuesto[Año];
Presupuesto[MesNumero]
);
TREATAS ( VALUES ( Productos[Categoria] ); Presupuesto[Categoria] )
)
Con cualquiera de estas técnicas obtenemos la posibilidad de integrar en nuestro análisis el presupuesto al nivel de detalle definido en el mismo. Si el usuario selecciona un contexto de filtro no disponible en el presupuesto para obtener un análisis más granular, como por ejemplo si profundiza a nivel de producto en la matriz anterior, el valor de la medida se repite para cada producto, lo que puede causar interpretaciones erróneas:

El mismo problema surge si el usuario intenta segmentar los datos por cualquier atributo de dimensiones no incluidas en el presupuesto, como las de Clientes o Empleados. En estos casos, si no se dispone de un algoritmo que nos permita asignar o distribuir los valores calculados del presupuesto para granularidades inferiores a las definidas, siempre es mejor usar una técnica para mostrar u ocultar medidas según el nivel de granularidad de los datos subyacentes, con el objetivo de evitar mostrar el presupuesto en contextos de filtro para los que no se encuentra disponible.
Para hacer esto, podemos crear una medida que verifique que el número de registros activos en cada tabla del modelo de datos sea igual al número de filas en la misma tabla, que, a su vez, corresponda a la granularidad de la tabla del presupuesto en el mismo contexto de filtro. Por ejemplo, el número de filas en la tabla Producto se calcula con la función CALCULATE(), que modifica el contexto de filtro en la tabla Productos utilizando la función ALLEXCEPT(), eliminando cualquier filtro que no sea la columna Categoría, que es la única referencia a la dimensión Productos que tenemos en la tabla de presupuesto. Tras realizar la misma comprobación con el resto de tablas con algún atributo disponible en nuestros pronósticos, si queremos comprobar también el uso de atributos de dimensiones no incluidas, deberemos comparar el número de filas en el contexto de filtro, con el número de filas de toda la tabla. En nuestro caso, el código a implementar es el siguiente:
EsPresupuestoOK =
(
COUNTROWS ( Productos )
= CALCULATE (
COUNTROWS ( Productos );
ALLEXCEPT ( Productos; Productos[Categoria] )
)
)
&& (
COUNTROWS ( Calendario )
= CALCULATE (
COUNTROWS ( Calendario );
VALUES ( Calendario[AñoMesNumeros] );
ALL ( Calendario )
)
)
&& ( COUNTROWS ( Clientes ) = COUNTROWS ( ALL ( Clientes ) ) )
&& ( COUNTROWS ( Empleados ) = COUNTROWS ( ALL ( Empleados ) ) )
&& ( COUNTROWS ( Pais ) = COUNTROWS ( ALL ( Pais ) ) )
Finalmente, podemos crear la medida que mostrará el valor del presupuesto solamente cuando el contexto de filtro definido por el usuario corresponda a una granularidad disponible en la tabla de presupuesto, devolviendo BLANK() en caso contrario:
Presupuesto2019 :=
IF ( [EsPresupuestoOK]; Ventas[VentasPresup2019]; BLANK () )
La siguiente imagen muestra los valores de Presupuesto2019 por mes, categoría y producto. Como podemos ver, al nivel de producto, el presupuesto no muestra ningún importe, porque no se verifica la comparación que hemos definido programáticamente.

Todas estas técnicas se basan en propagar filtros a lo largo del modelo de datos mediante la creación de relaciones virtuales entre atributos dimensionales entre los que, aun existiendo una relación lógica, no es posible establecer una relación física, al no cumplir ninguna de las columnas el requisito de estar constituida por valores únicos. Este enfoque es correcto si la cardinalidad de la relación es relativamente baja o si se trata de un modelo de datos complejo donde relaciones físicas adicionales pueden generar referencias circulares u otros efectos secundarios no deseados.
En casos contrarios debemos siempre considerar la posibilidad de implementar dimensiones puente que nos permitan establecer relaciones físicas. A continuación, profundizaremos en las posibilidades de integración de previsiones presupuestarias mediante este método y aprovecharemos para implementar algoritmos que nos permitan asignar o distribuir nuestras previsiones a granularidades distintas a las detalladas en el presupuesto.
Relaciones varios-a-varios con dimensiones auxiliares y asignación de valores a granularidades no disponibles
Imaginémonos que disponemos de la siguiente tabla de presupuesto de ventas anual, con detalle por categoría de producto y país del cliente, y con 3 escenarios para los importes del mismo:

Como podemos observar, la única granularidad temporal de la que disponemos es el año, desconocemos por completo la distribución trimestral o mensual de las ventas, por lo que el potencial analítico que nos proporciona el presupuesto es verdaderamente escaso. Necesitamos, nuevamente, trabajar con datos a distintas granularidades y encontrar una forma de proyectar las ventas presupuestadas al nivel de granularidad temporal deseado.
Antes de ello, vamos a encargarnos de establecer el escenario del presupuesto como un atributo más, de manera que tengamos un registro por cada combinación de categoría, país y escenario. Esta tarea es muy sencilla, solo tenemos que anular la dinamización de las columnas correspondientes en el editor de consultas y conseguiremos el resultado deseado:

Volviendo al aspecto temporal de nuestro presupuesto, una técnica simple de asignación consiste en dividir el importe anual presupuestado entre 12, para disponer de los importes mensuales, pero a no ser que se trate de una empresa con una demanda tremendamente estable, sería una solución bastante problemática. Una mejor idea es redistribuir el presupuesto con el mismo porcentaje de asignación mensual producido el año anterior en las ventas reales, de manera que esperemos una estacionalidad similar a la ya ocurrida.
Para llevar esto a cabo, construiremos con DAX una tabla de presupuesto mensual, que, manteniendo la granularidad en la categoría de producto, el país del cliente y el escenario presupuestado, nos permita redistribuir mensualmente nuestras previsiones. Vamos a ver el código completo y a continuación lo explicamos:
EVALUATE
CALCULATETABLE (
FILTER (
ADDCOLUMNS (
ADDCOLUMNS (
ADDCOLUMNS (
ADDCOLUMNS (
GENERATE (
VALUES ( Presupuesto[Escenario] );
CROSSJOIN (
CROSSJOIN ( DISTINCT ( Productos[Categoria] );
DISTINCT ( Clientes[Pais] ) );
DISTINCT ( Calendario[MesNumero] )
)
);
«Ventas»; CALCULATE (
SUMX ( Ventas;
Ventas[Cantidad] * Ventas[Precio] ) );
«VentasAnuales»; CALCULATE (
SUMX ( Ventas; Ventas[Cantidad] * Ventas[Precio] );
ALL ( Calendario[MesNumero] )
)
);
«Porcentaje»; DIVIDE ( [Ventas]; [VentasAnuales] );
«PresupuestoAnual»; LOOKUPVALUE (
Presupuesto[Presupuesto2019];
Presupuesto[Categoria]; Productos[Categoria];
Presupuesto[Pais]; Clientes[Pais];
Presupuesto[Escenario]; Presupuesto[Escenario]
)
);
«PresupuestoMensual»; [PresupuestoAnual] * [Porcentaje]
);
«Fecha»; DATE ( 2019; [MesNumero]; 1 )
);
[Ventas] > 0
);
FILTER ( VALUES ( Calendario[Año] ); Calendario[Año] = 2018 )
)
Resumiendo, con este código lo que hacemos es, en primer lugar, crear una consulta con todas las combinaciones existentes entre los atributos presentes en nuestro presupuesto y el mes del año, y a continuación calculamos las ventas del año 2018 correspondientes a cada registro de dicha consulta. Posteriormente, calculamos las ventas anuales (mediante la eliminación del filtro de MesNumero con la función ALL()) para seguidamente, calcular el porcentaje que del total anual de ventas ha supuesto cada mes del año 2018. Más tarde, aplicamos dicho porcentaje a nuestro presupuesto anual (incorporado en nuestra consulta mediante la función LOOKUPVALUE()) para finalmente, con el objetivo de poder establecer una relación física con nuestra dimensión temporal, crear otra columna para asignar a cada registro el primer día del mes correspondiente. Ya tenemos nuestra consulta de presupuesto mensual incorporada en el modelo:

Una vez realizado el paso anterior, todavía nos encontramos con algún problema. Al igual que antes, necesitamos poder establecer relaciones con las tablas de Productos y Clientes, con el fin de poder segmentar, mediante el uso de los atributos de dichas dimensiones, nuestras ventas reales y presupuestadas en una misma visualización. En este caso, no vamos a establecer relaciones virtuales mediante el uso de TREATAS() u otras funciones como hicimos en el apartado anterior, ahora vamos a introducir relaciones físicas en el modelo de datos mediante la creación de dimensiones auxiliares con valores únicos, que actúen como puente entre las tablas de búsqueda y el presupuesto.
Para crear una dimensión auxiliar del país del cliente que nos permita establecer una relación física entre la tabla Clientes y nuestro presupuesto mensual, creamos una nueva tabla calculada con el siguiente código:
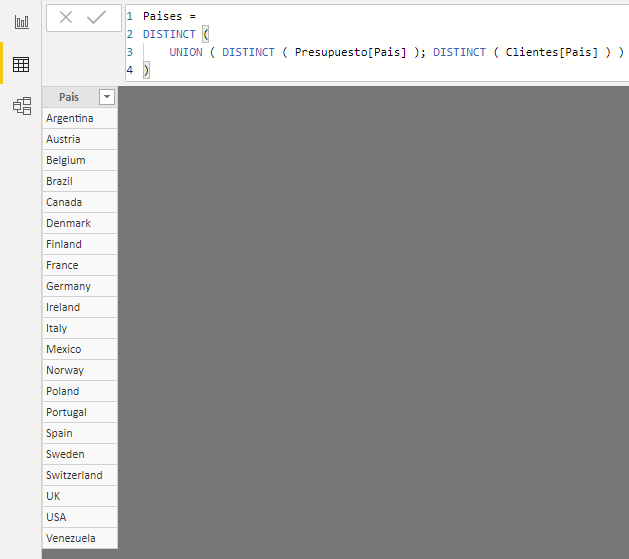
Una vez tenemos nuestra tabla de valores únicos podemos establecer las relaciones con la dimensión correspondiente y con el presupuesto:

Utilizando la columna País de nuestra tabla auxiliar podemos segmentar correctamente tanto las ventas como el presupuesto con sus distintos escenarios:

Llegados a este punto, a pesar de que el modelo funciona correctamente, desde la óptica del usuario resulta extraño, y aunque ocultemos en la vista de informes el atributo País de la dimensión Clientes es probable que se pregunte: ¿por qué tengo algunos atributos correspondientes a los clientes en una tabla y el país lo tengo en otra?
Para que el modelo siga siendo intuitivo para el usuario final podemos habilitar la dirección de filtro cruzado entre la dimensión Clientes y nuestra tabla auxiliar:

Realizando la misma tarea para la dimensión Productos, podremos ocultar definitivamente nuestras tablas auxiliares en la vista de informes, puesto que simplemente las hemos utilizado para propagar los filtros a la tabla de presupuesto, y el usuario podrá utilizar los atributos desde su dimensión original para filtrar y segmentar las tablas de hechos sin ningún problema. El modelo quedaría finalmente de la siguiente manera:

La activación del filtro cruzado bidireccional en un modelo de datos tabular es una decisión que hay que tomar con mucha cautela, puede crear rutas ambiguas en la cadena de relaciones y resultar en modelos muy peligrosos en los que los números se vuelven impredecibles.
En este caso, no estamos tratando de establecer una relación entre dos dimensiones (lo que podríamos denominar una relación varios-a-varios en un sentido estricto), si no solamente resolver el problema de la incompatibilidad de granularidad entre una dimensión y una tabla de hechos. Ahora, si nos centramos en las categorías de producto, todas las medidas reciben el contexto de filtro de la tabla puente en caso de que se seleccione una o más categorías. Si no hay filtros activos en dicho atributo, el filtro no se aplica, por lo que solamente pagamos el precio de la propagación del filtro de forma bidireccional cuando esto es imprescindible.
En realidad, ya no es necesario crear este tipo de tablas puente para resolver el problema. Desde que Microsoft introdujo los modelos compuestos en Power BI, también existe la posibilidad de usar una relación de varios-a-varios directamente entre dos tablas sin necesidad de habilitar el modo bidireccional como podemos ver en la siguiente imagen, aunque dejaremos este tema para una articulo posterior sobre las denominadas «relaciones débiles» en Power BI:

Volviendo a nuestro modelo, ¿qué ocurre si el usuario intenta segmentar los datos en función de otros atributos dimensionales no disponibles en nuestro presupuesto? pues al igual que en el apartado anterior de este artículo, donde creábamos relaciones virtuales para solventar el problema de trabajar con información a distinta granularidad, los resultados no serían correctos.
Para solucionar esta situación podemos recurrir, al igual que en dicho apartado, a mostrar las medidas solo en aquellos casos en los que la granularidad sea la correcta, es decir, esté disponible en nuestras previsiones presupuestarias, mediante el cálculo de una medida similar a EsPresupuestOK, o, análogamente a lo realizado con la dimensión temporal en este apartado, proyectar los importes hacia los demás atributos de ambas dimensiones en función de las proporciones que podemos deducir de las ventas reales del año anterior. En el siguiente apartado vamos a realizar dicho proceso de forma dinámica, sin materializar los resultados en una nueva consulta.
Asignación dinámica de previsiones presupuestarias a atributos dimensionales no disponibles en el presupuesto
En este apartado volvemos a utilizar la tabla de presupuesto anual original, dejando de lado el presupuesto mensual creado por nosotros con DAX.
Primero, tenemos que calcular el porcentaje con el que asignaremos los importes presupuestados al resto de atributos de las dimensiones presentes en el presupuesto. Para ello, utilizamos una vez más las ventas reales del año anterior, dividiéndolas entre dichas ventas calculadas a la granularidad en la que se elaboró el presupuesto originalmente:
Pct =
DIVIDE (
[Ventas2018];
CALCULATE (
[Ventas2018];
ALL ( Productos );
VALUES ( Productos[Categoria] );
ALL ( Clientes );
VALUES ( Clientes[Pais] );
ALL ( Calendario[MesNumero] );
ALL ( Calendario[Mes] )
)
)
Y posteriormente, aplicamos el porcentaje calculado al importe presupuestado:
PresupDin2019 =
SUM ( Presupuesto[Presupuesto2019] ) * [Pct]
De esta forma, no necesitamos precalcular los valores de forma estática y materializarnos en el modelo de datos para usarlos posteriormente, si no que podemos utilizar DAX para calcular los valores sobre la marcha, durante el tiempo de procesamiento de nuestras medidas. Con este último cálculo podemos asignar, de una forma completamente dinámica y basándonos en las ventas del año anterior, los importes presupuestados a la granularidad que nos interese en cada momento, pudiendo filtrar y segmentar nuestras medidas mediante el uso de cualquier atributo dimensional:

Yendo un poco más lejos
Una vez tenemos nuestras previsiones presupuestarias completamente integradas en el modelo de datos, podemos seguir usando DAX para mucho más. Por ejemplo, mediante la aplicación de factores de corrección al presupuesto, basados en las desviaciones experimentadas entre los importes reales y los pronósticos, podemos ajustar dinámicamente las previsiones y obtener visualizaciones como la siguiente, donde la diferencia entre los valores reales y presupuestados de enero a marzo se utiliza para modificar el presupuesto de ventas del resto del año:

Si los presupuestos que se realizan en la empresa son más completos, es decir, se presupuestan también unidades de producto o servicio, costes, tamaño y cuota de mercado etc… es relativamente sencillo diseñar herramientas completas de control presupuestario en Power BI, que nos proporcionarán la capacidad de analizar minuciosamente las causas de las desviaciones experimentadas basándonos en los componentes del denominado presupuesto flexible, para interpretar dichas desviaciones de manera correcta y facilitar el diseño e implantación de planes para la corrección de las mismas cuando estas pongan en peligro la obtención del resultado presupuestado:

Conclusiones
El modelo tabular es realmente potente. En este artículo hemos visto cómo podemos utilizar DAX para crear modelos de datos relativamente complejos sin necesidad de importar información adicional, manejar de forma coherente información a distinta granularidad y construir completas soluciones de control presupuestario, herramienta clave para el control de gestión, en función de los datos disponibles.
Las capacidades de modelado de datos de Power BI son las que verdaderamente le diferencian de otras herramientas populares que existen en el mercado y con las que habitualmente se compara, pero que en realidad solo actúan como instrumentos de reporting. Power BI nos ofrece una solución completa de modelado y visualización de datos, con un conjunto cada día más amplio de capacidades para diseñar y enriquecer modelos formados por información proveniente de múltiples orígenes distintos, e integrarla de forma congruente entre sí, con el propósito de facilitar la toma de decisiones en tiempo real y a todos los niveles de la organización.
Todo el código DAX de este artículo ha sido formateado con «DAX Formatter»
