
Introducción
Un escenario muy frecuente cuando utilizamos bases de datos relacionales como origen de datos principal de un modelo que reproduce un proceso de negocio, como pueden ser las ventas de una empresa, es encontrarnos con dos tablas de hechos con distinta granularidad para describir el mismo proceso. Una de ellas contendrá un registro por cada ticket, albarán o factura emitida con los atributos generales de fecha, cliente, base imponible, impuesto etc., y la otra irá un poco más allá y registrará las ventas a nivel de cada producto vendido, es decir, existirá un registro por cada línea de detalle dentro de cada documento.
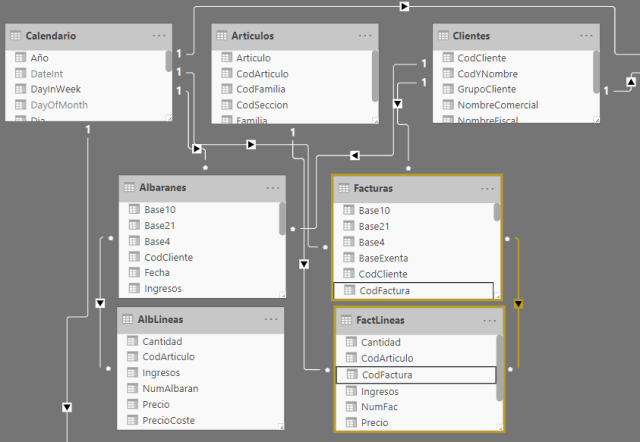
En la siguiente imagen podemos ver un ejemplo de esta situación, donde tanto los albaranes como las facturas presentan una estructura de datos del tipo descrito:
Esta situación es distinta a la que surge cuando tenemos una tabla por cada nivel dentro de una jerarquía dimensional, como puede ser la jerarquía natural que se forma cuando tenemos productos, familias de productos y secciones de productos. Aunque en este caso existen también varios niveles de datos, todos ellos corresponden a atributos dimensionales almacenados con distinta granularidad.
En el caso que nos ocupa en este artículo, que podemos denominar como estructura cabecera/detalle, ambas tablas forman una jerarquía que modela los hechos de un mismo proceso de negocio, aunque su granularidad sea distinta. Podemos decir que este tipo de estructura surge cuando existe algún tipo de relación entre dos tablas de hechos.
Como podemos ver en la imagen anterior, cada uno de los niveles de las tablas de hechos se relaciona directamente con alguna de las dimensiones del modelo, pero no con todas. Por ejemplo, si existe alguna métrica en la cabecera, como puede ser un descuento o un coste logístico, no podría segmentarse en función de los atributos de la dimensión producto, al no estar directamente relacionadas ambas tablas. Este tipo de métricas corresponden con un documento de venta en su conjunto, pero no con cada una de las líneas que componen el mismo.
Cómo modelar correctamente esta situación
Es posible pensar que mediante el uso de filtro cruzado entre ambas tablas de hechos podemos resolver esta situación:
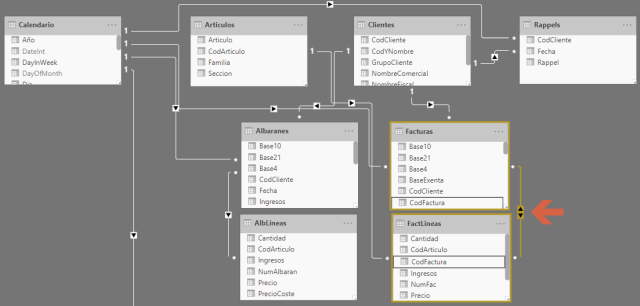
Tanto si habilitamos la dirección de filtro cruzado en Power BI como si utilizamos un patrón en DAX de relación varios-a-varios, si utilizamos un atributo de producto como segmentador, el modelo será capaz de propagar el filtro tanto a la tabla que contiene la cabecera de las facturas como a la que contiene los detalles de cada una de ellas. Si creamos una visualización obtendremos un resultado que aparentemente computa los importes que nosotros buscamos, es decir, la suma de los importes descontados segmentados por cada uno de los artículos:
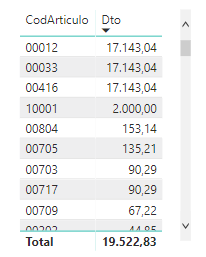
Aunque obtenemos un importe de descuento distinto para cada código de artículo, este cálculo es erróneo. Por cada producto, el filtro de contexto mantendrá visibles todas las facturas que contienen dicho producto y sumará todos los descuentos aplicados a cada factura en su conjunto. Como podemos observar en la visualización anterior, solo al nivel del total general el cálculo será correcto, es decir, cuando no existe ningún filtro en los atributos de la dimensión de producto. No necesitamos los descuentos a nivel de detalle de cada producto, sino que los necesitamos al nivel de detalle de cada venta individual de producto.
Por lo tanto, cambiar el modelo de datos simplemente habilitando la propagación de los filtros entre ambas tablas de hechos en las dos direcciones no nos da lo que buscamos; que es reproducir un esquema en estrella, con una sola tabla de hechos que contenga toda la información relevante del proceso de negocios correspondiente y pueda filtrarse y segmentarte por cada uno de los atributos de cualquier dimensión.
La forma de solucionar esta situación es calcular el porcentaje de descuento que corresponde a cada una de las facturas, para posteriormente aplicar dicho porcentaje a cada una de las líneas de cada factura y desnormalizar completamente (aplanar) el resto de columnas de la cabecera en la tabla de detalles.
Utilizando DAX
Si no podemos modificar la estructura de las consultas que componen el modelo y tenemos que trabajar directamente con un modelo como el de las imágenes anteriores, podemos realizar este proceso utilizando el lenguaje DAX.
Tanto para calcular el % que supone el descuento sobre la base imponible de cada factura y posteriormente aplicarlo a cada una de las líneas de detalle podemos usar el siguiente código DAX genérico:
SalesHeader[DiscountPct] =
DIVIDE (
SalesHeader[TotalDiscount],
SUMX (
RELATEDTABLE ( SalesDetail ),
SalesDetail[Unit Price] * SalesDetail[Quantity]
)
)
SalesDetail[LineDiscount] =
RELATED ( SalesHeader[DiscountPct] ) * SalesDetail[Unit Price] * SalesDetail[Quantity]
Utilizando M
Si podemos realizar transformaciones en las consultas de forma que apliquemos una optimización estructural de los datos antes de que estos sean cargados al modelo, podemos realizar los mismos pasos que hemos hecho en DAX desde el editor de consultas de Power BI, que en mi opinión es una solución mucho más elegante.
En primer lugar, obtenemos el descuento en términos porcentuales respecto al total de la base imponible en la tabla Facturas con una columna calculada:

Una vez obtenido dicho porcentaje, solo tenemos que combinar las dos consultas que registran el proceso de facturación y expandir la columna de descuento en términos porcentuales, así como otras columnas que queramos trasladar hacia la tabla de líneas de facturas, que será, en el nuevo modelo, la única tabla de hechos que registra el proceso de facturación de la empresa:

Una vez hemos realizado este proceso, solo tendremos que cargar al modelo la tabla de detalles de factura:
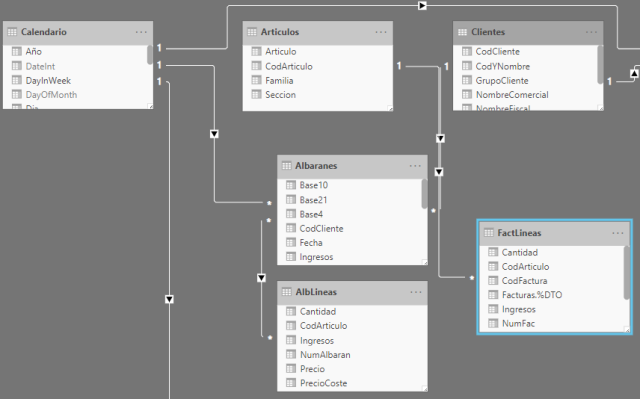
Si realizamos los mismos pasos con las consultas que registran los albaranes de la empresa, así como con cualquier otras del mismo tipo, podremos recrear un modelo en estrella que nos ofrecerá todas las ventajas de dicha estrucutra, entre las que se encuentra el aprovechar el hecho de que la mayoría de los motores analíticos (incluyendo el de Power BI y SQL Server Analysis Services) están altamente optimizados para manejar la información de este tipo de estructuras, con una tabla de hechos por cada proceso de negocio.
Todo el código DAX de este artículo ha sido formateado con «DAX Formatter»
